


TIGER: using artificial intelligence to discover our collections
The State Library of NSW has almost 4 million digital files in its collection. A ‘digital file’ is pretty much anything you can access online: photographs, paintings, books, objects, manuscripts and more. Many of these files have been digitised, while others are digital in their original format, such as contemporary digital photography or social media archives.
With such a large collection, it’s impossible to catalogue everything in detail. Except for culturally and historically significant material, we catalogue our collections only at the ‘top’ level.
For example, a catalogue record for an album of photographs will tell you everything we know about the album itself, such as who took the photos, where they were taken and if any significant people, places or events are in them. We aren't able to describe each photograph in detail (the ‘file’ level), unless the album was acquired with individual captions already included.
This is typical practice for collecting institutions, but it creates challenges when you’re trying to search through a pool of millions of digital images in our catalogue. It’s even harder if you don’t know exactly what you’re looking for.
To tackle this problem, TIGER was born.
The Library has a tiger?
TIGER is the name of our project that uses artificial intelligence (AI) to automatically create descriptive keyword tags for our image collections. TIGER stands for Tagging Images Generically for Exploration and Research. (Basically, we picked an animal we all liked and made the acronym fit!)
The TIGER project involved a lot of experimenting and controlled testing, including a pilot project back in 2017 in partnership with the University of Technology Sydney. Its main outcome has been to tag our digital collections at a file level with descriptive keywords to make digital items easier to find.
Here are some of the results:

An image of a horse drawn cart, tagged with animal, horse, wagon, horse cart, transportation, wheel.

An image of two men sitting in the grass, one holding a drum, tagged with person, man, drum, musical instrument.

A painting of two kangaroos in a field, tagged with animal, wallaby, kangaroo, macropodidae, painting.
How does TIGER work?
To begin, we run our digital images through three different off-the-shelf tagging programs to create a list of tags for each file (Google Cloud Vision, Amazon Image Recognition and Microsoft Computer Vision). We originally intended to compare the results and pick the single most suitable program for our collections, but we found after ongoing testing that they all had their own strengths so we decided instead to use them together.
On the lists of tags, each keyword has a percentage rating that represents the level of confidence in the word’s accuracy — the higher the number the more likely the term will be correct. We wanted to find a way to compare and extract the best results of the combined keywords and remove any that were not accurate or useful. But we faced a huge challenge in creating a process to do this programmatically and for many millions of images. And so, TIGER was born.
TIGER’s algorithm analyses the tags generated for individual images and applies a series of rules to sort the raw data in an attempt to isolate the most accurate and relevant keyword tags. It took months of tweaking the rules and retagging test batches to find the ‘sweet spot’. As well as calculating average confidence level ratings, our rules account for other factors like frequent keyword occurrences, repetition and relevancy rankings.
The rules don’t guarantee 100% accurate tags, but they often get us much closer to describing and, importantly, searching for images in ways we couldn’t before.
How do these tags help researchers?
Let’s look at a collection of watercolour paintings of birds by ES Derby. His digitised journal holds 136 paintings of different birds. When you look at the record for this collection in our current catalogue, you see image thumbnails in a grid:

If you take a look at the metadata in the catalogue record, the collection has been tagged with high level subject headings like ‘Birds--New South Wales’.
But what if you’re researching pelicans? You might search in the Library’s current catalogue using the term of ‘pelican’ and get a list of results. After scrolling the list, you will see that Derby’s volume of watercolour birds comes up at #28. It’s a promising start, but the thumbnail for the catalogue listing is not a pelican, it looks like a black cockatoo, the first image from the set. You can assume this appears in your results list because the word pelican is somewhere in the record and that the collection may also include an image of a pelican.
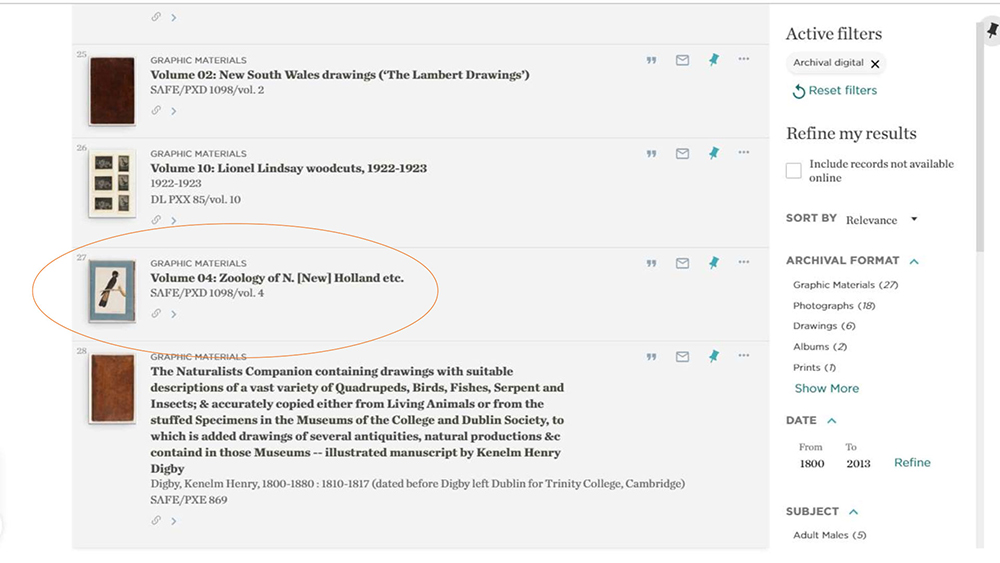
When you open the catalogue record, you see the grid of 136 thumbnails as shown above, and you have to browse all of them yourself in the hope of finding a watercolour that features a pelican.
But what if we could make the process for finding pelicans in the State Library’s collection easier?
Using our TIGER method, we generated keyword tags for all images within Derby’s collections. This was one of the results:

A painting of a pelican, tagged with bird, animal, pelican.
What this means is that if you now conduct the same search for ‘pelican’ in our new Digital Collections portal, you will find the following results:
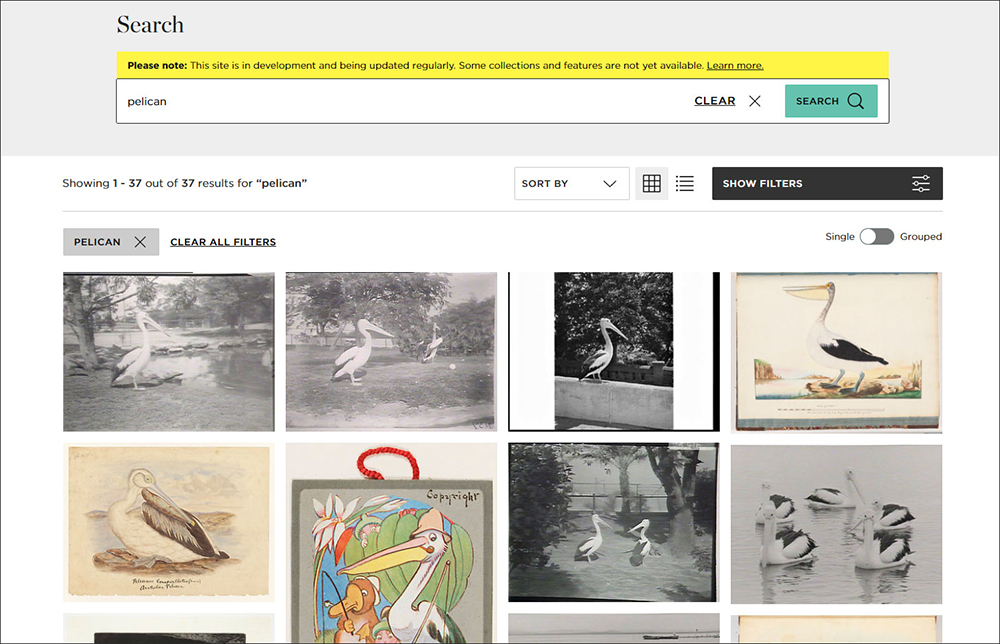
In the results Derby’s pelican is fourth, sitting among other pelicans from the collection. You didn’t need to know the name of the artist or the format it was created in — instead, in a matter of seconds, you could search for a single keyword and get exactly the kind of results you were looking for.
Powered by TIGER tags, we can now offer an experience that allows you to search for or browse things like the Library’s colourful collection of badges, photographs of historical swimming pools, or even explore Latin classifications of animal species such as Cynthia (subgenus). Our team has had many moments of surprise and delight over the last 12 months as we discovered the ways TIGER has cast new light on our digital collections.
Taming the TIGER
Given that this process is machine generated, TIGER tags are never going to be perfect. We’ve found our fair share of redundant tags like ‘human’, wrong tags such as ‘rug’ applied to all the coins in our collection, and a few cheeky results like this gorgeous Archibald Prize painting by Desmond Digby being tagged with ‘child art’. Machines don’t always get it right, but with TIGER we’ve can filter down as much possible to the most accurate tags, and the few unhelpful ones that slip through can be easily ignored.
Eventually, readers will be able to give feedback on tags, letting us know when one is wrong and also which tags are especially useful in their research.
Machine and human partnership
For the many thousands of items that have already been given detailed tags by cataloguers, we still run the images through TIGER. We display the machine-generated tags alongside those our staff have created. Often the two types of tags complement each other, with information from the catalogue, such as locations or named people, enhanced when paired with more detailed tags from TIGER. Some examples include this windmill from Port Macquarie, these skiers in Mt Kosciusko National Park and this military officer from 1856.
TIGER into the future
Even though we’ve been working on the TIGER process for over a year now, it still has a long way to go. The beauty of machine learning is that the technology gets better the more you use it. Our plans for improving TIGER include refining the accuracy of tags, creating taxonomy groupings of similar keywords and subject headings, and finding a way for readers to explore the full list of tags we've created (already in the tens of the thousands). We also want to explore the use of Library-specific wordlists for creating tags.
In a future blog post we’ll dive further into the technical details of how our TIGER algorithm works, but for now we hope you have fun discovering the many treasures in our Digital Collections, including some we probably haven’t discovered yet ourselves!
Jenna Bain, Digital Projects Leader & Robertus Johansyah, Back-end Developer.